zur Startseite von 2ask
zur Startseite von 2askZusammenhangsmaß für zwei nominalskalierte Variablen
Die gebräuchlichsten Maße für den Zusammenhang zweier nominalskalierter Variablen sind PHI und Cramers V.
PHI wird berechnet, wenn der Zusammenhang zweier Merkmale mit jeweils genau zwei Merkmalsausprägungen untersucht werden soll (d.h. bei einer 2x2-Kreuztabelle). Cramers V wird berechnet, wenn ein Merkmal mehr als 2 mögliche Ausprägungen besitzt.
Um die Zusammenhangsmaße PHI und Cramers V berechnen zu können muss vorher die Berechnung des Faktors chi-Quadrat erfolgen.
Chi-Quadrat basiert auf der folgenden Überlegung:
Besteht ein Unterschied zwischen der existierenden (empirischen) Beziehung und der theoretischen (zufälligen) Beziehung?
Erstellung von Kreuztabellen
Die Vorgehensweise, wie eine Kreuztabelle erstellt wird möchten wir Ihnen an dieser Stelle anhand eine Beispiels verdeutlichen.
Eine Kindergartengruppe besteht aus insgesamt 20 Kindern (N=20), die Hälfte sind Jungen, die Hälfte Mädchen. Die Kinder wurden gefragt, ob sie lieber mit Lego oder mit Puppen spielen. Die Antworten (= empirische Verteilung) der Kinder sehen Sie in nachfolgender Abbildung:
Man kann erkennen, dass die Gruppe aus insgesamt 10 Mädchen (50%) und 10 Jungen (50%) besteht, wobei insgesamt 12 Kinder (60%) angeben, dass sie am liebsten mit Lego spielen und 8 Kinder (40%) geben an, dass sie Puppen bevorzugen.
Die Erstellung der theoretische Verteilung basiert auf folgender Annahme:
Wenn kein Zusammenhang zwischen diesen Variablen (Geschlecht des Kindes und Lieblingsspielzeug) besteht, dann dürfte es nur vom Zufall abhängen, ob z.B. ein Junge lieber mit Lego oder Puppen spielt.
Konkret gehen Sie bitte folgendermaßen vor:
Bilden Sie eine Tabelle mit gleicher Anzahl an Zeilen und Spalten wie in der empirischen Verteilung. Übernehmen Sie die Randhäufigkeiten der Zeilen und Spalten.
Es gilt:
Die Gesamtanzahl der Kinder, die Jungen sind beträgt 10.
Die Gesamtanzahl der Kinder, die am liebsten mit Lego spielen beträgt 12.
Es müssten also (10*12)/N (N= Gesamtanzahl Kinder, hier: N=20) = (10*12)/20 = 6 Jungen angeben, dass sie am liebsten mit Lego spielen
D.h.: Um die theoretische Verteilung für die einzelnen Felder zu erstellen multipliziert man die entsprechenden Randhäufigkeiten und teilt diese durch die Gesamtanzahl N.
Die Zellen werden nun wie folgt berechnet: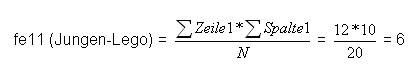
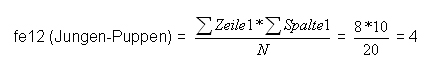

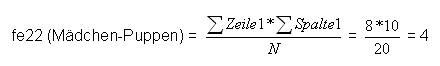
Übersichtlicher dargestellt ergibt sich für die theoretische Verteilung:
Oft kann es hilfreich sein, die theoretische Verteilung nicht in Form absoluter Zahlen, sondern als Anteile dazustellen. Dazu dividiert man die für die einzelnen Merkmale berechneten Anzahlen durch die Gesamtanzahl N. Es ergeben sich dabei folgende Anteile:
--> Nun wird die theoretische Verteilung mit der empirischen verglichen.
Dabei gilt:
Wird für Jungen, die mit Puppen spielen in der Realität der Kindergruppe (d.h. in der empirischen Verteilung) der Wert von 20% (der sich aus der theoretischen Verteilung ergibt, siehe oben) unterschritten (oder überschritten), dann tritt die Kombination dieser beiden Merkmale in der tatsächlichen (d.h. empirischen) Verteilung "überzufällig" selten (bzw. oft) auf.
--> Dies deutet darauf hin, dass zwischen den Variablen Geschlecht und Lieblingsspielzeug ein statistischer Zusammenhang besteht.
Erstellung von Kreuztabellen mit SPSS
Wählen Sie in SPSS das Menü „Analysieren“ --> „Deskriptive Statistiken“ --> „Kreuztabellen“.
Ordnen Sie nun die Variablen den Zeilen und Spalten zu.
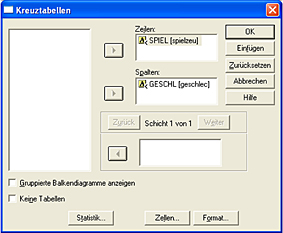
Klicken Sie nun auf den "Zellen"-Button. Es öffnet sich ein neues Fenster. Hier können Sie festlegen, ob Sie sich die empirische Verteilung (= Beobachtet) oder die theoretische Verteilung (= Erwartet) oder beide anzeigen lassen möchten.
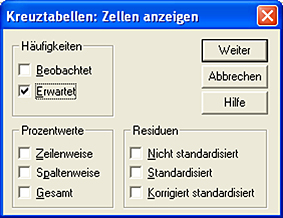
Aus Gründen der Übersichtlichkeit soll im Folgenden nur die theoretische Verteilung dargestellt werden. SPSS bestätigt dabei unsere manuell berechneten Ergebnisse:

Berechnung von chi-Quadrat
„Chi-quadrat“ lässt sich nach folgender Formel berechnen:
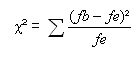
dabei gilt:
fb= absolute Häufigkeit der empirischen Verteilung
fe= absolute Häufigkeit der theoretischen Verteilung
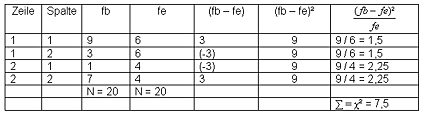
Bei der Berechnung von chi-Quadrat geht man folgendermaßen vor:
- Bestimmung von fb:
Übernahme der Daten aus der empirischen Verteilung - Bestimmung von fe
Übernahme der Daten aus der theoretischen Verteilung - Berechnung von Chiē nach obiger Formel
Berechnung von Phi - Koeffizient
Der PHI-Koeffizient bezeichnet den Zusammenhang zweier dichotomer Merkmale (Merkmale, die nur je zwei Ausprägungen annehmen können, z.B. Geschlecht, ja-nein oder haben - nicht haben). PHI wird also nur bei 2x2-Tabellen berechnet, d.h. wenn der Zusammenhang zwischen genau zwei Merkmalen (hier: Geschlecht und Lieblingsspielzeug) mit jeweils genau 2 Ausprägungen (Jungen-Mädchen; Lego-Puppen) berechnet wird.
Der PHI-Koeffizient kann mit Hilfe des chiē-Wertes auf folgende Art und Weise berechnet werden: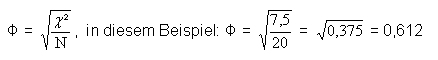
Die Berechnung von PHI kann auch ohne vorherige Berechnung von chiē erfolgen. Dazu muss man die gegebenen Daten in Anteile umrechnen.
Beispiel: mit N = 20 Kindern
Um PHI zu berechnen werden nun die Randsummen berechnet und dann die Anteile der Merkmalskombinationen.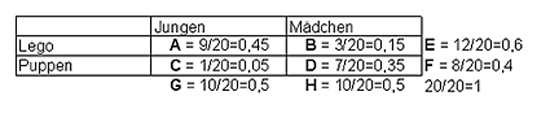
Die Formel für PHI lautet: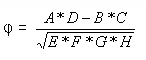
Für dieses Beispiel ergibt sich: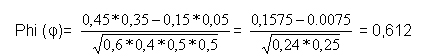
Berechnung von Cramers V
Cramers V ist ein Kontingenzkoeffizient, der ebenfalls auf chiē basiert und immer zwischen 0 und 1 liegt. Es handelt sich um eine Maßzahl für die Stärke des Zusammenhangs zwischen zwei nominalskalierten Variablen wenn (mindestens) eine der beiden Variablen mehr als zwei Ausprägungen hat (z.B. 5x4-Tabelle, 2x3-Tabelle).
Bei einer 2x2-Tabelle kann man Cramers V zwar berechnen, man sollte jedoch Phi als Maßzahl verwenden.
Cramers V berechnet sich folgendermaßen:
Mit:
n = Gesamtzahl der Fälle
R = der kleinere der beiden Werte: Anzahl Zeilen und Anzahl Spalten
Beispiel:
Um chiē zu berechnen muss wieder zuerst die Indifferenztabelle (= theoretische Verteilung) erzeugt werden. Die Felder werden dabei analog zur Berechnung der Felder bei Phi berechnet.
Beispiel: Feld links oben (Jungen - Lego)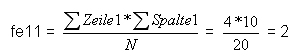
Es ergibt sich folgende theoretische Verteilung:
Dann kann chiē folgendermaßen berechnet werden: 
Mit
fb: Übernahme der Daten aus der empirischen Verteilung
fe: Übernahme der Daten aus der theoretischen Verteilung
Cramers V berechnet sich folgendermaßen: 
n = Gesamtzahl der Fälle - in unserem Fall: n = 20
R = der kleinere der beiden Werte: Anzahl Zeilen (hier 3) und Anzahl Spalten (hier 2) --> wähle Anzahl Spalten = 2

Interpretation
Cramers V liegt bei jeder Kreuztabelle - unabhängig von der Anzahl der Zeilen und Spalten - zwischen 0 und 1. Dieses Zusammenhangsmaß kann bei beliebig großen Kreuztabellen angewandt werden.
Cramers V = 0: es besteht kein Zusammenhang zwischen X (Geschlecht) und Y (Lieblingsspielzeug)
Cramers V = 1: es besteht ein perfekter Zusammenhang zwischen X und Y
| Da Cramers V immer positiv ist, kann keine Aussage über die Richtung des Zusammenhangs getroffen werden. |
In der Praxis findet man häufig folgende Interpretationen vor:
0,1 - 0,3 schwacher Zusammenhang
0,4 - 0,5 mittlerer Zusammenhang
> 0,5 starker Zusammenhang
Unser berechnetes Cramers V = 0,462 besagt, dass für das Beispiel ein mittelstarker Zusammenhang zwischen Geschlecht und Lieblingsspielzeug besteht.
Berechnung von PHI und Cramers V mit Hilfe von SPSS
In SPSS werden Phi und Cramers V immer zusammen ausgegeben. Gehen Sie dazu folgendermaßen vor:
Wählen Sie in SPSS „Analysieren“ --> „Deskriptive Statistiken“ --> „Kreuztabellen“.
Klicken Sie auf den "Statistiken"-Button. Es öffnet sich folgendes Fenster:
Die Berechnung mit SPSS bestätigt unser manuell berechnetes Ergebnis für den Phi-Koeffizient für das o.g. 2x2-Design: